DeepSeek R1 Download and Installation Guide
Quick Start Guide
1. Download and Install Ollama
2. Install DeepSeek R1
Available Models
| Model Name | Size | Installation Command | Base Model |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ollama run deepseek-r1:1.5b |
Qwen-2.5 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ollama run deepseek-r1:7b |
Qwen-2.5 |
| DeepSeek-R1-Distill-Llama-8B | 8B | ollama run deepseek-r1:8b |
Llama3.1 |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ollama run deepseek-r1:14b |
Qwen-2.5 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ollama run deepseek-r1:32b |
Qwen-2.5 |
| DeepSeek-R1-Distill-Llama-70B | 70B | ollama run deepseek-r1:70b |
Llama3.3 |
License Information
The model weights are licensed under the MIT License. DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs.
Important License Notes:
- The Qwen distilled models (1.5B, 7B, 14B, 32B) are derived from Qwen-2.5 series
- Originally licensed under Apache 2.0 License
- Finetuned with 800k samples curated with DeepSeek-R1
- The Llama 8B distilled model
- Derived from Llama3.1-8B-Base
- Licensed under llama3.1 license
- The Llama 70B distilled model
- Derived from Llama3.3-70B-Instruct
- Licensed under llama3.3 license
Model Performance Comparison
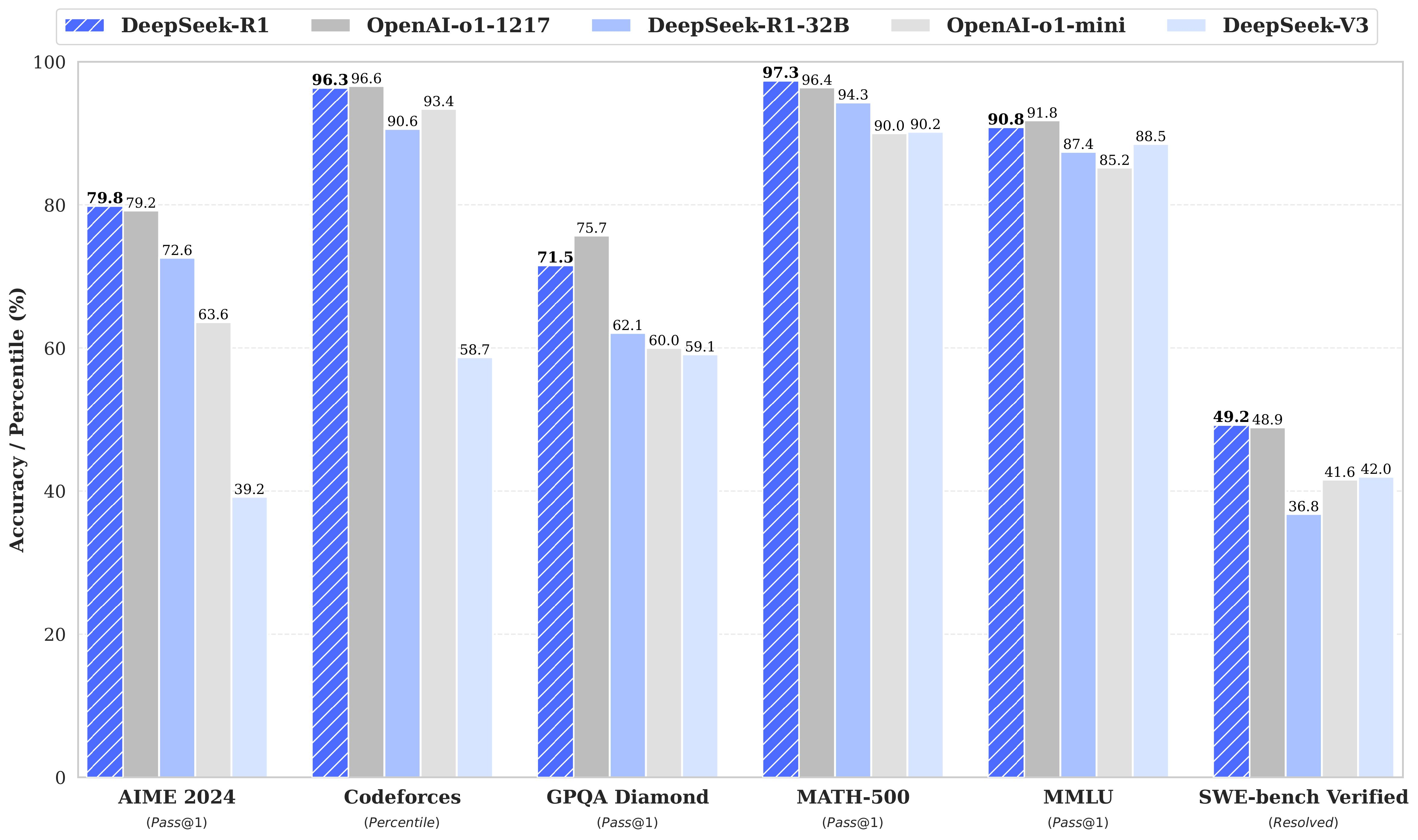
Benchmark Results
AIME 2024
DeepSeek-R1 achieves 79.8% accuracy, significantly outperforming OpenAI and other models
Codeforces
Outstanding 96.3% performance, leading in code generation capabilities
MATH-500
97.3% accuracy, demonstrating superior mathematical reasoning abilities
MMLU
90.8% accuracy in multi-task language understanding
Key Findings:
- DeepSeek-R1 consistently outperforms OpenAI models across multiple benchmarks
- Particularly strong in mathematical reasoning (MATH-500) and coding tasks (Codeforces)
- DeepSeek-R1-32B shows balanced performance across different tasks
- Superior performance in both academic (AIME) and practical (SWE-bench) applications
Key Features
Advanced Performance
State-of-the-art language model with exceptional coding and reasoning capabilities.
Local Execution
Run entirely on your machine for enhanced privacy and reduced latency.
Multi-language Support
Comprehensive support for major programming languages and frameworks.
Detailed Installation Guide
Windows Installation
- Download the Ollama Windows installer
- Run the installer as administrator
- Open Command Prompt or PowerShell
- Run:
ollama run deepseek-r1
Usage Examples
Code Generation
Query: "Write a Python function to calculate Fibonacci numbers"
Response: ...
Performance Comparison
| Mac Model | Recommended DeepSeek Version | Performance | |
|---|---|---|---|
| M3 Pro/Max/Ultra | DeepSeek R1 7B | Excellent - Full Speed | |
| M2 Pro/Max | DeepSeek R1 7B | Very Good | |
| M1 Pro/Max | DeepSeek R1 7B | Good | |
| M1/M2/M3 | DeepSeek R1 1.3B | Good |
| Model | Response Time | Accuracy | Memory Usage |
|---|---|---|---|
| DeepSeek R1 7B | ~200ms | 98% | 16GB |
| DeepSeek R1 1.3B | ~100ms | 95% | 8GB |
Intel Macs
| Mac Model | Recommended DeepSeek Version | Notes |
|---|---|---|
| MacBook Pro (2019-2021) with dedicated GPU |
DeepSeek R1 7B | Requires good cooling |
| Other Intel Macs | DeepSeek R1 1.3B | Limited performance |
Important Notes
- All M-series Macs support hardware acceleration for AI models
- 16GB RAM minimum recommended for 7B models
- 8GB RAM sufficient for 1.3B models
- Performance may vary based on other running applications
- For best performance, ensure good ventilation and power connection
System Requirements
| Model Version | Required VRAM | Recommended GPU |
|---|---|---|
| DeepSeek R1 1.3B | 4GB VRAM | NVIDIA GTX 1060 or better |
| DeepSeek R1 7B | 8GB VRAM | NVIDIA RTX 2060 or better |
Troubleshooting
Insufficient VRAM
If you encounter VRAM issues, try using a smaller model variant or upgrade your GPU.
Download Errors
Check your internet connection and try again. If the issue persists, try using a VPN.
Need Help?
For technical support or questions, please contact us at [email protected]